AI Hallucinations — Why They Happen and What You Can Do About Them
If you have used an AI assistant long enough, you have seen it. A confident answer that turns out to be completely wrong. A made-up statistic. A citation to a paper that does not exist. A plausible-sounding explanation of something that never happened.
This is called hallucination — and it is arguably the most important limitation to understand if you are using or building AI systems.
The good news: hallucination is predictable and partially manageable. The important thing to know upfront: it is not a bug that will disappear in the next model release. It is built into how these systems work.
🔗 Foundation for this post
This post builds directly on What is a Large Language Model (LLM)? — if you have not read it, start there. Understanding what an LLM is doing (predicting tokens, not looking up facts) is the key to understanding why hallucination happens.
What hallucination actually means
In AI, hallucination means the model produces output that is presented with confidence but is factually wrong, unsupported, or entirely fabricated.
The term comes from the way the output resembles a hallucination in humans — internally coherent, seemingly real, but detached from actual reality. The model is not lying. It has no concept of truth or falsehood. It is generating what statistically comes next — and sometimes, what comes next is wrong.
| Type of hallucination | What it looks like | Example |
|---|---|---|
| Factual error | States a wrong fact confidently | ”The Eiffel Tower was built in 1901” — it was 1889 |
| Fabricated citation | Invents a paper, book, or URL that does not exist | Cites a 2022 Harvard study with a real-looking DOI that leads nowhere |
| Entity confusion | Mixes up two real things or attributes the wrong property | Attributes a quote to the wrong person |
| Outdated information | Correct at training time but no longer true | States a CEO or policy that has since changed |
| Faithfulness error | Distorts or contradicts the source it was given | Summarises a document but changes a key number |
| Instruction drift | Drifts away from what was asked in a long conversation | Ignores a constraint mentioned earlier in the chat |
Why it happens — the structural reason
This is the part most AI articles skip. Hallucination is not caused by the model being poorly trained or having a bug. It is a consequence of what the model fundamentally is.
An LLM is trained to predict the most plausible next token given everything before it. It has no internal mechanism to verify whether a claim is true. It has no lookup table, no search engine, no way to say “let me check.” It produces what is statistically likely to follow — and sometimes, a confident-sounding wrong answer is statistically what follows in the patterns it learned.
💡 The training signal problem
During training, models are penalised for saying ‘I don’t know’ and rewarded for producing fluent, confident-sounding text. This means the model learns to generate plausible answers even when its internal representations are uncertain. It has been trained to be helpful — and sometimes being wrong feels more helpful than saying nothing.
| Root cause | What it means |
|---|---|
| No truth mechanism | The model has no way to verify a claim against reality — it predicts, it does not check |
| Training data errors | The internet contains errors, contradictions and outdated information — the model learned from all of it |
| Knowledge cutoff | Anything after the training cutoff is unknown — confident guesses fill the gap |
| Rare topic exposure | Topics underrepresented in training data are more likely to hallucinate — the model has less signal to draw from |
| Long context drift | In very long conversations or documents, the model can lose track of earlier constraints and contradict itself |
| Overconfidence by design | Training incentivises confident, fluent output — uncertainty is not naturally surfaced |
How bad is it — real numbers
Hallucination rates vary significantly depending on the task, the model and whether mitigation is in place. These are verified figures from 2025-2026 research:
| Domain / task | Hallucination rate | Source / context |
|---|---|---|
| General conversational tasks | 31% prevalence globally | Real-world conversational benchmark, 2025 |
| Structured analysis tasks | 15% – 52% across models | 2026 benchmark across 37 commercial LLMs |
| Medical case summaries | 43% – 64% | Without mitigation prompts, medical AI research 2025 |
| Legal domain queries | 69% – 88% | High-stakes legal query studies, 2025-2026 |
| Code generation (fake libraries) | Up to 99% | When prompted with non-existent library names |
| With prompt-based mitigation | Reduced by ~22 percentage points | 2025 Nature study — GPT-4o dropped from 53% to 23% |
| Grounded summarisation (top models) | 0.7% – 1.5% | With RAG and grounding, 2025 benchmarks |
📌 The takeaway from the numbers
Unmitigated hallucination rates in high-stakes domains (legal, medical) are alarmingly high. With proper grounding and mitigation, rates drop dramatically — sometimes to under 2%. The gap between unmitigated and mitigated is where good AI implementation practice lives.
The types that matter most in enterprise use

Fabricated citations — particularly dangerous
When an LLM invents a paper, study or URL, it does not flag it as uncertain. It presents it with the same confidence as a real source. In legal, medical or financial contexts, acting on a fabricated source can cause real harm. Always verify citations from any AI-generated content independently.
Faithfulness errors — the RAG trap
Even when you provide source documents to the model (via RAG or file upload), it can still hallucinate by distorting or contradicting what the document says. The model does not simply copy — it generates. A number can be misread, a condition dropped, a nuance reversed. Review AI summaries of important documents carefully, especially around numbers, dates and conditions.
Outdated information — the cutoff problem
Every LLM has a training cutoff. After that date, the model has no direct knowledge of events. If asked about something post-cutoff, it may either correctly say it does not know, or — more dangerously — generate a plausible-sounding answer based on pre-cutoff patterns. For anything time-sensitive, always verify with a current source.
What actually reduces hallucination
Hallucination cannot be eliminated entirely with current LLM architectures. It can be significantly reduced with the right approach.
| Mitigation approach | How it works | Effectiveness |
|---|---|---|
| RAG — Retrieval Augmented Generation | Give the model relevant source documents at query time — it answers from evidence not memory | High — reduces hallucination dramatically for knowledge-intensive tasks |
| Prompt-based mitigation | Instruct the model to cite sources, say ‘I don’t know’ when uncertain, and avoid guessing | Moderate — 2025 Nature study showed ~22 percentage point reduction |
| Temperature reduction | Lower temperature makes token selection less random — more conservative output | Low alone — helps slightly but not a primary fix |
| Output verification / judges | A second model evaluates the first model’s output for faithfulness before it is shown to the user | High for automated pipelines — adds latency but catches errors pre-delivery |
| Structured output constraints | Force JSON or fixed schema — reduces open-ended generation where hallucination flourishes | Moderate — effective for structured data tasks |
| Human review | For high-stakes outputs, a human checks the response before action is taken | Highest reliability — required for medical, legal, financial decisions |
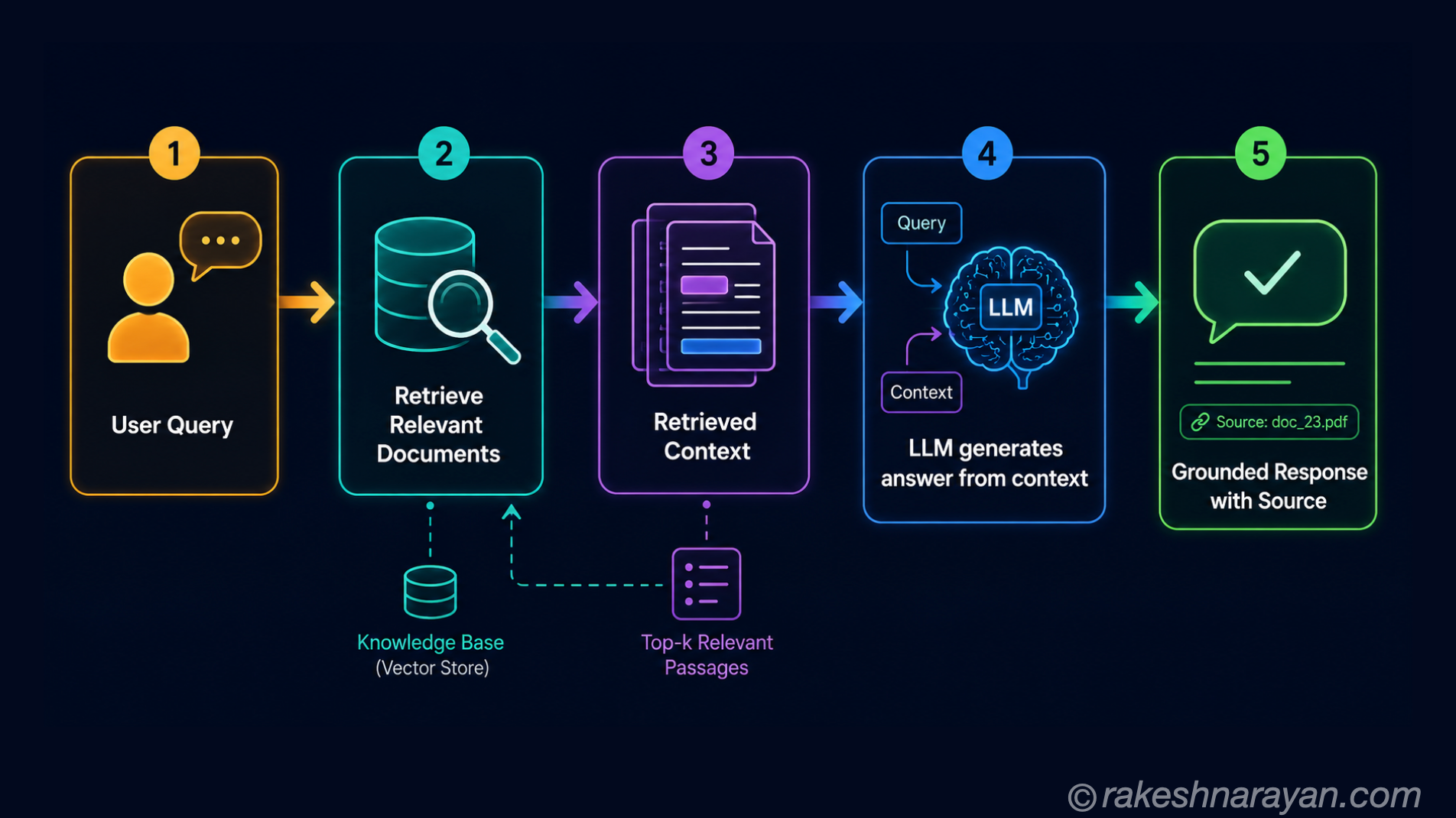
💡 RAG is the most impactful single fix
Retrieval Augmented Generation — giving the model verified source documents to answer from — reduces hallucination more than any other single technique. Instead of relying on what the model memorised during training, it reads and synthesises from provided context. The next post in this series covers RAG in full.
What this means in practice — SAP and enterprise contexts
If you are evaluating or deploying AI tools in an SAP or enterprise context, hallucination should be part of every conversation. A few scenarios where it matters directly:
| Scenario | Hallucination risk | Mitigation |
|---|---|---|
| SAP Joule answering process questions | Medium — answers from SAP’s grounded knowledge graph | Joule uses RAG over SAP documentation — verify for edge cases |
| LLM summarising a contract or policy document | High — faithfulness errors common | Always review the original document for numbers, conditions and exceptions |
| AI generating ABAP or SQL code | Medium-High — may reference non-existent function modules or tables | Test all generated code — never deploy without review |
| Chatbot answering customer queries | High if ungrounded | Ground with product/policy knowledge base via RAG — add human escalation |
| LLM analysing a financial report | High for specific figures | Cross-reference every number against the original document |
The honest summary
| Question | Honest answer |
|---|---|
| Will hallucination be fixed eventually? | Partially. Frontier models improve continuously — but structural elimination is not expected with current architectures |
| Are newer models better? | Generally yes — but some reasoning models trade off accuracy for depth. Always check benchmarks for your specific use case |
| Can I trust an AI answer? | Depends on the task. For well-grounded factual queries with RAG — often yes. For open-ended knowledge retrieval — verify |
| What is the safest approach? | Use AI for drafting, summarising and structuring. Keep humans in the loop for decisions, numbers and high-stakes outputs |
| Is SAP Joule affected? | Yes — all LLMs hallucinate. Joule uses grounding techniques that reduce rates significantly for SAP-domain queries |
What to take away
Hallucination is not a reason to avoid AI. It is a reason to use AI thoughtfully. Every tool has limitations — a calculator cannot write, a spreadsheet cannot reason. An LLM should not be trusted blindly for factual verification, citation, or high-stakes decisions without grounding or human review.
Understanding why it happens — token prediction without truth verification — gives you the mental model to know when to trust the output and when to check. That distinction is where the real value of AI experience lives.
🔗 Related posts on this site
What is a Large Language Model (LLM)? — the foundation: why LLMs predict rather than think. Coming next: RAG — Retrieval Augmented Generation — the single most effective tool for reducing hallucination in enterprise AI systems. rakeshnarayan.com/articles/
Published on rakeshnarayan.com — Articles