What is a Large Language Model (LLM)?
ChatGPT. Claude. Gemini. Llama. Joule. These are the names you hear every week now. They are all powered by large language models — and most people who use them every day have only a rough idea of what is actually happening inside.
That rough idea is enough to use an LLM. It is not enough to use one well, to evaluate AI claims critically, or to make decisions about where AI fits in your organisation.
This post builds the real mental model — what an LLM is, how it was trained, what it is doing when it responds to you, and what it fundamentally cannot do.
The one-sentence definition
A large language model is a software system trained on enormous amounts of text that has learned to predict what text should come next in any given sequence.
That is it. Everything else — the conversations, the code, the summaries, the reasoning — is a consequence of doing that one thing extraordinarily well, at enormous scale.
What makes it ‘large’
Three things define the scale of a modern LLM:
| What is large | What it means | Scale in 2026 |
|---|---|---|
| Training data | The text the model learned from — books, websites, code, scientific papers | Trillions of words — a significant fraction of human written knowledge |
| Parameters | The numerical values adjusted during training — the model’s ‘knowledge’ is encoded here | Billions to trillions — GPT-4 is estimated at ~1.8 trillion, smaller models at 7-70 billion |
| Compute | The processing power used for training | Thousands of specialised AI chips running for months |
💡 Parameters are not memories
A common misconception is that an LLM ‘stores’ facts like a database. It does not. Parameters are numerical weights — mathematical values adjusted during training so the model produces better outputs. Knowledge is distributed across billions of these weights, not stored in individual cells. This is why LLMs can be confidently wrong — there is no lookup to verify against.
Tokens — the unit of language
LLMs do not work with words. They work with tokens.
A token is a chunk of text — roughly a word, part of a word, or a punctuation mark. The model breaks everything — input and output — into tokens before processing.
| Text | Approximate tokens |
|---|---|
| Hello | 1 token |
| Hello, world! | 4 tokens — Hello / , / world / ! |
| tokenisation | 3 tokens — token / isa / tion |
| SAP S/4HANA | 5 tokens — SAP / S / / / 4 / HANA |
| 750 words of text | Approximately 1,000 tokens |
| This entire blog post | Approximately 1,800-2,200 tokens |
Why tokens matter: LLMs have a context window — the maximum number of tokens they can process at once, including both your input and their output. Modern models in 2026 have context windows ranging from 32,000 to over 1 million tokens, but context limits still affect how much information a model can work with in a single conversation.
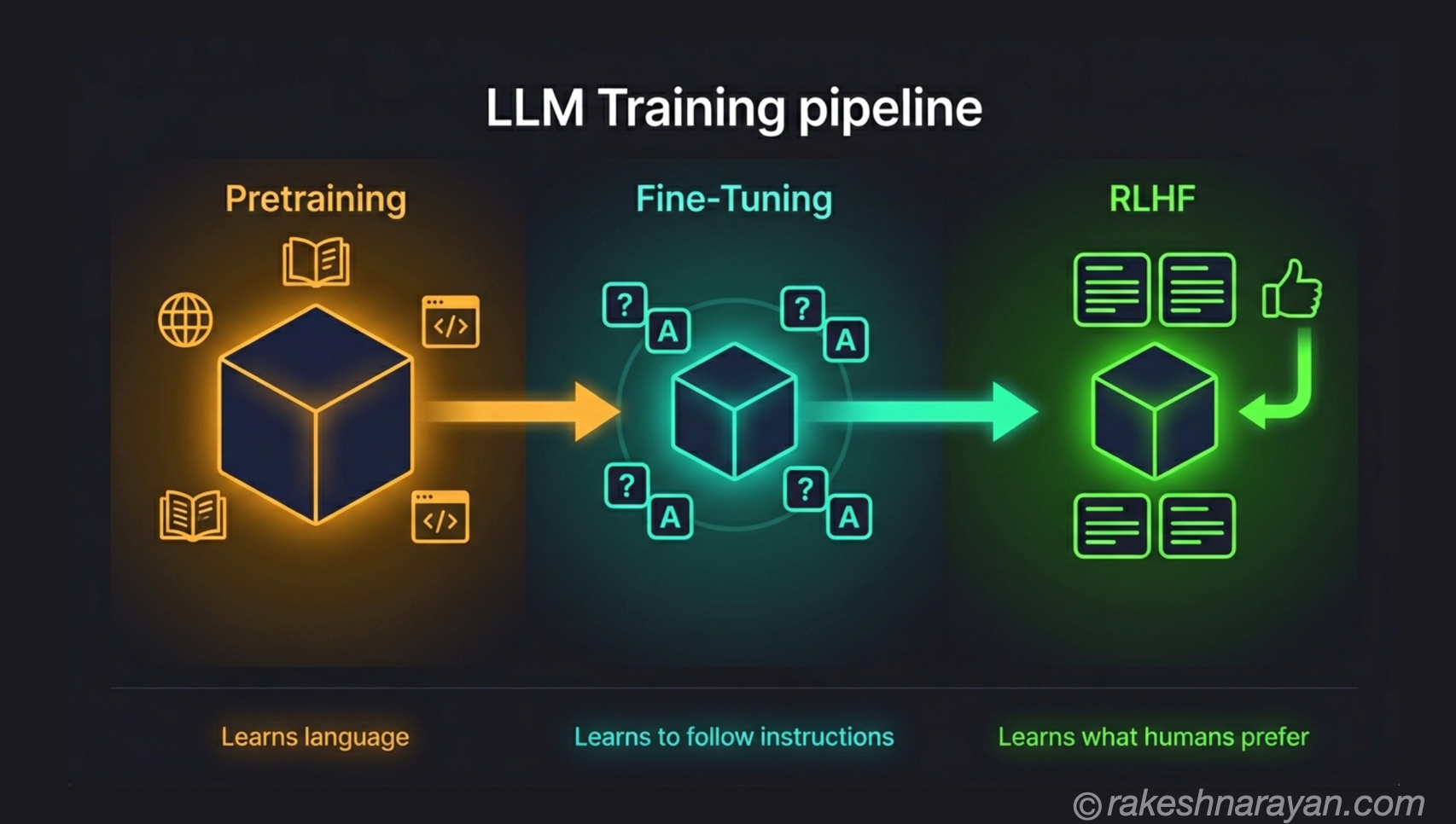
How an LLM is trained
Training happens in stages. Understanding the stages explains a lot about why LLMs behave the way they do.
Stage 1 — Pre-training
The model is exposed to an enormous dataset of text — typically a filtered and deduplicated mix of web pages, books, code repositories, scientific papers and other sources. The training task is simple: given a sequence of tokens, predict the next one.
This happens billions of times, with the model’s parameters being adjusted slightly after each prediction based on how wrong it was. Over months and enormous compute, the model becomes very good at predicting plausible next tokens — which means it has implicitly learned grammar, facts, reasoning patterns, code syntax and much more.
Stage 2 — Fine-tuning and alignment
A pre-trained model is not yet safe or useful for conversation. The second stage — typically involving Reinforcement Learning from Human Feedback (RLHF) or similar techniques — trains the model to be helpful, honest, and avoid harmful outputs.
Human raters compare model responses and rate them. The model learns from these ratings to produce responses that humans prefer. This is what turns a raw text predictor into a usable assistant.

Dedicated Article on How LLMs Are Trained
What the model is doing when it responds
When you send a message to an LLM, here is what happens:
- Your message is broken into tokens
- Each token is converted into a numerical vector (an embedding) that represents its meaning in context
- The transformer architecture processes these vectors through many layers, each attending to relationships between all tokens in the context
- The model produces a probability distribution over every possible next token
- One token is selected based on that distribution — either the most likely one, or sampled with some randomness (this is what temperature controls)
- That token is added to the context and the process repeats — one token at a time — until the response is complete
💡 The model does not plan its answer
This is the most important thing to understand. An LLM does not think about what to say and then say it. It generates one token at a time, each one based on everything before it. There is no internal plan, no scratchpad, no reasoning separate from the output itself. What looks like reasoning is pattern completion — extremely sophisticated pattern completion, but pattern completion nonetheless.
What LLMs are good at
| Capability | Why LLMs excel |
|---|---|
| Text generation | This is literally what they were trained to do — producing fluent, coherent text |
| Summarisation | Pattern of input text → shorter version is well-represented in training data |
| Translation | Multilingual training data allows cross-language pattern matching |
| Code generation | Code from GitHub, Stack Overflow and documentation is in training data |
| Question answering | For questions with answers well-represented in training data |
| Tone and style adaptation | Massive exposure to varied writing styles allows mimicry |
| Instruction following | Fine-tuning specifically trained the model to follow instructions |
What LLMs cannot do — and why
| Limitation | Why it exists |
|---|---|
| Real-time information | Training data has a cutoff date — the model does not know what happened after it was trained |
| Precise arithmetic | LLMs predict plausible tokens, not calculated values — use a calculator for maths |
| Guaranteed factual accuracy | No lookup mechanism — confident-sounding wrong answers are a structural property, not a bug |
| True reasoning | Output is token prediction — complex multi-step reasoning is often unreliable without tools |
| Private data access | The model only knows what was in its training data — not your organisation’s documents |
| Memory across sessions | By default, each conversation starts fresh — there is no persistent memory |
A practical heuristic that holds up well: LLMs are excellent at tasks where being approximately right is valuable — drafting, summarising, explaining, translating, generating options. They are unreliable at tasks where being exactly right is required — precise numbers, current facts, citations, legal or medical specifics. If the cost of being wrong is low, use the output directly. If the cost of being wrong is high, use the output as a starting point and verify.
⚠️ Hallucination is structural, not accidental
When an LLM states a false fact confidently, this is called hallucination. It is not a bug that will be fixed — it is a consequence of how LLMs work. They predict plausible text, not verified facts. The model has no internal mechanism to know whether a claim is true. Verification against external sources — via RAG or other grounding techniques — is required for high-stakes factual use cases.
LLMs you are using today — a reference
| Model | Creator | Notable for |
|---|---|---|
| GPT-4o / GPT-4.1 | OpenAI | Powers ChatGPT — one of the most widely used consumer LLMs |
| Claude (Sonnet, Opus) | Anthropic | Strong reasoning, large context window, focus on safety |
| Gemini 2.0 / 2.5 | Google DeepMind | Deep integration with Google products and search |
| Llama 3.x | Meta | Open-weight model — can be run locally or self-hosted |
| Mistral / Mixtral | Mistral AI | Efficient open models, popular for enterprise self-hosting |
| SAP Joule | SAP | SAP’s AI copilot — powered by LLMs, embedded across SAP products |
💡 SAP Joule and LLMs
SAP Joule is SAP’s generative AI assistant, embedded across S/4HANA, SuccessFactors, Ariba and BTP. It is powered by LLMs and uses SAP’s business context — your data, your processes — to give relevant answers inside SAP applications. Understanding what an LLM can and cannot do is directly relevant to understanding what Joule can and cannot reliably do.
The mental model — in one view
| Concept | One-line summary |
|---|---|
| LLM | A model trained to predict the next token in a sequence — at massive scale |
| Token | The unit of text an LLM processes — roughly a word or word-fragment |
| Parameters | Numerical weights encoding the model’s learned patterns — not a database of facts |
| Pre-training | Learning from trillions of tokens of text — the model absorbs language and knowledge |
| Fine-tuning | Shaping the model to be helpful and safe using human feedback |
| Temperature | Controls randomness in token selection — higher = more creative/unpredictable |
| Context window | How much text the model can see at once — input + output combined |
| Hallucination | Confidently wrong output — structural, not accidental — plan for it |
| Joule | SAP’s LLM-powered assistant — embedded in SAP products, grounded in SAP context |
What to take away
An LLM is a pattern predictor — the largest and most sophisticated one ever built. It learned from an extraordinary breadth of human-written text, and that gives it the ability to generate fluent, knowledgeable, contextually aware responses across almost any topic.
But it is not a reasoning engine, it is not a database, and it does not verify what it says. Understanding those limits is not pessimism — it is how you use LLMs effectively and build systems around them that are actually reliable.
Everything that follows in AI — RAG, agents, fine-tuning, hallucination mitigation — builds directly on this foundation.
🔗 Coming next in the AI series
The next posts in this series cover:
AI hallucinations — why they happen (the structural explanation in full)
RAG — retrieval augmented generation (how to ground LLMs in real data)
AI agents — what they are and how they work (how LLMs go from answering questions to taking actions)
Published on rakeshnarayan.com — Articles
URL: https://rakeshnarayan.com/articles/what-is-a-large-language-model-llm/
Did you enjoy this article?
Let me know — it takes one click.
0 Comments
Leave a Comment
Your comment has been submitted and will appear after review.