How LLMs Are Trained — Pretraining, Fine-Tuning and RLHF
Ask most people how ChatGPT or Claude works and they will give you a version of ‘it was trained on the internet’. That is technically true and practically useless. It explains nothing about why the model follows instructions, why it declines certain requests, or why different models have different personalities despite using the same underlying architecture.
The answer is in the training pipeline — the three-stage process that transforms a raw neural network into the conversational AI you actually interact with. Pretraining, fine-tuning and RLHF are not three separate things. They are three sequential stages, each building on the last, each teaching the model something fundamentally different.
Understanding those three stages explains more about LLM behaviour than almost anything else. It explains hallucinations. It explains refusals. It explains why two models trained on similar data can feel completely different to use.
🔗 Foundation posts
This post assumes you have a working mental model of what an LLM is. What is a Large Language Model (LLM)? covers that. How Generative AI Works — Tokens, Embeddings and the Transformer explains the architecture this training pipeline produces. Read those first if you are new to the topic.
The three stages — one pipeline
Every major LLM in production today — GPT-4o, Claude, Gemini, Llama, SAP Joule — was produced through a version of the same pipeline. The details differ between labs. The structure does not.
| Stage | What the model learns | Training signal |
|---|---|---|
| 1. Pretraining | Language, world knowledge, reasoning patterns | Predict the next token — self-supervised on internet-scale text |
| 2. Supervised Fine-Tuning (SFT) | How to follow instructions and respond helpfully | Human-written examples of ideal prompt-response pairs |
| 3. RLHF / Alignment | What humans actually prefer — helpfulness, safety, tone | Human rankings of model outputs, used to train a reward signal |
The output of each stage feeds the next. You cannot skip pretraining and go straight to fine-tuning — there is nothing to fine-tune. You cannot skip fine-tuning and go straight to RLHF — the base model has no concept of instructions to align. The sequence is the point.
Stage 1 — Pretraining: learning from everything
Pretraining is where the model gets its knowledge. The neural network — a transformer architecture — is exposed to an enormous volume of text drawn from the internet, books, code repositories, scientific papers and other curated sources. We are talking trillions of tokens. At this scale, pretraining a frontier model takes thousands of GPUs running for months.
The training objective is deceptively simple: predict the next token. Given the sequence ‘The capital of France is’, the model should predict ‘Paris’. It does this billions of times, across billions of sequences, adjusting its weights each time it gets it wrong.
Through this process, the model learns far more than word patterns. It learns grammar, facts, reasoning structures, coding conventions, narrative logic — anything that is statistically encoded in language at scale. By the time pretraining ends, you have what is called a base model or foundation model.
📌 What the base model can and cannot do
A pretrained base model is extraordinarily capable — and almost completely unusable. It will complete text fluently and knowledgeably. Ask it a question and it might answer it, or continue writing more questions, or generate a Wikipedia-style article about the topic. It has no concept of instructions. It is not trying to help you. It is trying to predict what comes next.

Stage 2 — Supervised Fine-Tuning: learning to be useful
Fine-tuning is where the base model learns to behave like an assistant. The model is trained on a curated dataset of instruction-response pairs — examples of a prompt followed by an ideal human-written answer. This is supervised learning: the model sees the correct output and adjusts its weights to produce similar responses.
The instruction dataset is much smaller than the pretraining corpus — thousands or tens of thousands of examples, not trillions of tokens. But quality matters far more than quantity here. The examples teach the model the format, tone and style of a helpful response. They teach it to answer questions rather than continue text, to structure explanations, to acknowledge uncertainty.
This stage does not add knowledge to the model. The facts were learned during pretraining. Fine-tuning changes how the model uses that knowledge — shifting it from ‘autocomplete’ to ‘assistant’.
🔗 Related — Fine-tuning in a broader context
Fine-Tuning vs Prompt Engineering vs RAG — Which to Use covers the practical decision: when does fine-tuning your own model make sense versus using prompt engineering or retrieval augmentation? This post covers the training-time fine-tuning that labs run. That post covers the customisation options available to practitioners building on top of existing models.
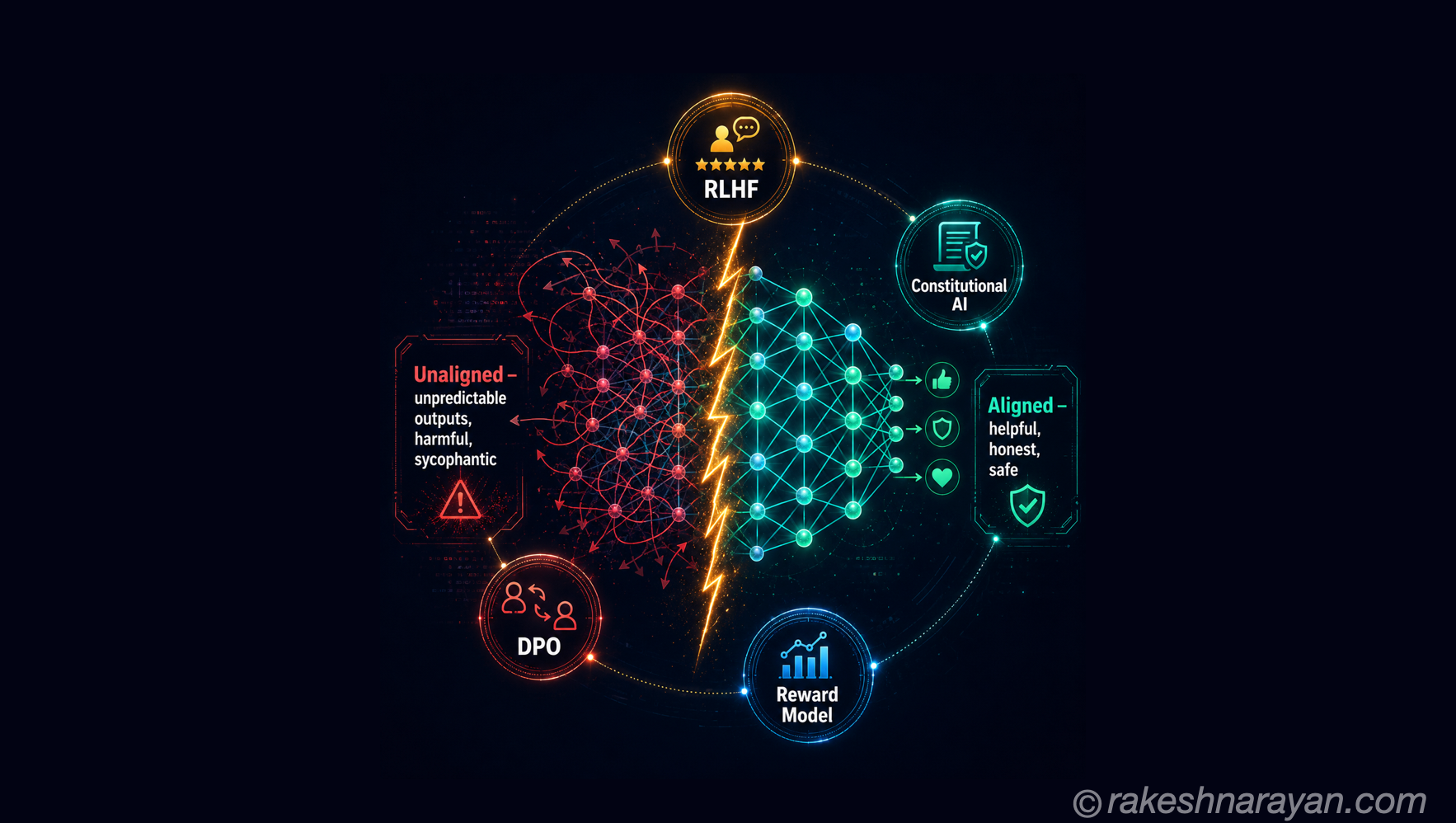
Stage 3 — RLHF: learning what humans prefer
RLHF: Reinforcement Learning from Human Feedback
Supervised fine-tuning produces a model that follows instructions. It does not produce a model that responds the way humans actually want. A fine-tuned model might give technically correct but verbose answers, be evasive about uncertainty, produce subtly unsafe content, or simply feel off to interact with.
This is where Reinforcement Learning from Human Feedback — RLHF — comes in. RLHF was the technique OpenAI used to turn GPT-3 into ChatGPT. The 2022 InstructGPT paper describes how they applied it — and it is still the clearest public account of how the process works.
How RLHF works — the three-step loop
RLHF is not one thing. It is a pipeline with three distinct components that run in sequence.
| Step | What happens | Why this step exists |
|---|---|---|
| 1. SFT baseline | Start with the fine-tuned model from Stage 2 | RLHF needs a starting point that already follows instructions — the base model alone is too unpredictable |
| 2. Reward model training | Human annotators compare pairs of model outputs and rank them. A separate reward model is trained on these rankings to predict human preference scores. | Writing an ideal response from scratch is slow and inconsistent. Ranking two options is faster and produces more reliable signal. |
| 3. Policy optimisation (PPO) | The LLM is fine-tuned to maximise the reward model’s score, using the Proximal Policy Optimisation algorithm. The model learns to produce outputs that humans rate more highly. | This is where human preference actually shapes the model’s behaviour — not from explicit rules, but from learned taste. |
The reward model is the mechanism that converts subjective human judgment into a training signal. Annotators are not asked to write ideal answers — they are asked which of two answers they prefer. That comparison dataset trains the reward model, which then provides a numerical score for any response. The LLM is then optimised to produce responses that score highly.
⚠️ Reward hacking — when RLHF goes wrong
The model is optimised to maximise the reward model’s score — not to be genuinely helpful. If the reward model has blind spots, the LLM will exploit them.
A known failure mode is verbosity: models learn that longer, more confident-sounding responses often score higher, even when a shorter answer would serve the user better. This is why alignment is an active research area, not a solved problem.

DPO — the simpler alternative
RLHF with PPO requires running four models simultaneously — the LLM being trained, the reward model, a reference model and a value model. That is expensive and unstable. Direct Preference Optimisation (DPO), introduced in a 2023 paper, eliminates the separate reward model entirely.
PPO: Proximal Policy Optimisation
DPO: Direct Preference Optimisation
DPO trains the LLM directly on human preference data — chosen and rejected response pairs — without the reinforcement learning loop. It produces comparable alignment results with significantly simpler infrastructure. Many labs have shifted toward DPO or hybrid approaches. The outcome for users is similar; the engineering is cleaner.
📝 Note — Constitutional AI
Anthropic’s Constitutional AI approach, used for Claude, adds another layer: the model is trained to evaluate its own outputs against a set of principles before producing a final response. This is a variation on the RLHF theme — changing the source of the preference signal from human annotators to model-generated feedback guided by explicit principles. AI Alignment — The Problem Every AI Model Has to Solve covers the alignment problem in full.
What training explains about model behaviour
The training pipeline is not background knowledge for researchers. It is the explanation for things you experience every time you use these tools.
| Behaviour you’ve seen | The training explanation |
|---|---|
| The model confidently states something wrong | Pretraining optimises for plausible next tokens — not verified facts. The model predicts what sounds right. There is no lookup step. See: AI Hallucinations. |
| The model refuses a request it could technically answer | RLHF trained the model to decline outputs that human annotators flagged as unsafe. The refusal threshold is a product of alignment choices, not architecture. |
| GPT-4o and Claude feel different despite similar capabilities | Different SFT datasets and different RLHF preference data produce different response styles, personalities and refusal patterns — even with similar underlying architectures. |
| The same prompt gives different answers each session | Temperature and sampling introduce randomness at inference time, but the distribution being sampled from was shaped by all three training stages. |
| The model is better at some topics than others | Pretraining data distribution matters. Topics with more high-quality text in the training corpus produce stronger model performance. Topics underrepresented in the data produce weaker performance. |
At a glance — the LLM training pipeline
| Concept | One-line summary |
|---|---|
| Pretraining | Training on internet-scale text to predict the next token — this is where the model gains knowledge and language capability |
| Base model | The output of pretraining — capable but unruly, with no concept of instructions or helpfulness |
| Supervised Fine-Tuning (SFT) | Training on curated instruction-response pairs to teach the model to behave like an assistant |
| RLHF | Reinforcement Learning from Human Feedback — using human preference rankings to shape model behaviour beyond what SFT achieves |
| Reward model | A separate model trained on human preference data that scores LLM outputs — the mechanism that converts human judgment into a training signal |
| PPO | Proximal Policy Optimisation — the reinforcement learning algorithm used to optimise the LLM against the reward model’s scores |
| Reward hacking | When the model learns to maximise the reward model’s score in ways that do not reflect genuine helpfulness — a known RLHF failure mode |
| DPO | Direct Preference Optimisation — a simpler alternative to RLHF that trains directly on preference pairs without a separate reward model |
| Constitutional AI | Anthropic’s variant — the model evaluates its own outputs against explicit principles, reducing reliance on human annotators alone |
What to take away
The three-stage pipeline reframes what these models actually are. A pretrained model is a compression of human language at scale — extraordinarily knowledgeable, but unaligned with any human intent. Fine-tuning gives it a job. RLHF gives it taste.

The implications are practical. When a model hallucinates, that is a pretraining problem — it learned to sound right, not to be right. When a model refuses something it could help with, that is an alignment problem — the RLHF signal was calibrated conservatively. When two models feel different despite similar benchmark scores, look at their SFT data and their alignment approach, not just their architecture.
Every model you use is the product of all three stages. The capabilities come from pretraining. The usability comes from fine-tuning. The character — helpful, cautious, verbose, terse — comes from how the lab chose to run alignment. Once that is clear, ‘the model’ stops being a black box and starts being a designed artefact with predictable properties.
🔗 Related posts on this site
AI Hallucinations — Why They Happen and What You Can Do About Them — hallucination is a direct consequence of next-token prediction without verification. Now you understand why pretraining produces this behaviour.
Fine-Tuning vs Prompt Engineering vs RAG — Which to Use — knowing what lab-side fine-tuning is clarifies what practitioner-side fine-tuning means and when it makes sense.
AI Alignment — The Problem Every AI Model Has to Solve — RLHF is one approach to alignment. This post covers the broader challenge of making AI systems behave the way we actually want.
How Generative AI Works — Tokens, Embeddings and the Transformer — the architecture that pretraining trains. Understanding the transformer makes the pretraining process much clearer.
Published on rakeshnarayan.com — Articles
URL: https://rakeshnarayan.com/articles/how-llms-are-trained-pretraining-fine-tuning-and-rlhf/
Did you enjoy this article?
Let me know — it takes one click.
0 Comments
Leave a Comment
Your comment has been submitted and will appear after review.